
Uitlegbare AI in de praktijk – lezing dag van de FG
| Sieuwert van Otterloo |
Artificial Intelligence
Privacy

Dit artikel is een samenvatting van de workshop “Uitlegbare AI in de praktijk”, die gegeven is op de Dag van de FG op 1 juni 2023. De dag van de FG is een congres voor functionarissen gegevensbescherming (FG’s). Dit zijn de toezichthouders op naleving van de AVG binnen bedrijven. FG’s hebben steeds meer te maken met geautomatiseerde besluiten. In deze workshop kijken we naar een aantal vragen en oplossingen over de uitlegbaarheid van algoritmes.
Algoritmes voor leningen
Een bekend besluit in de financiële sector is het beoordelen en goedkeuringen van leningaanvragen. Als iemand een huis wil kopen en daarvoor geld wil lenen, moet de bank beoordelen op basis van inkomen, leenbedrag en andere factor of de bank het risico wil nemen. Voor banken is het van belang dit besluit snel te nemen, en het ligt dus voor de hand dat zij AI of data science gebruiken. Traditioneel worden er regels gebruikt voor deze beoordeling. De bekendste regel is dat iedereen maximaal 4.5 maal zijn inkomen mag lenen. Technisch gezien is dit een algoritme, zoals hieronder weergegeven. Dit laat zien dat algoritmische besluiten niet nieuw zijn, en dat niet ieder algoritme moeilijk uitlegbaar is.
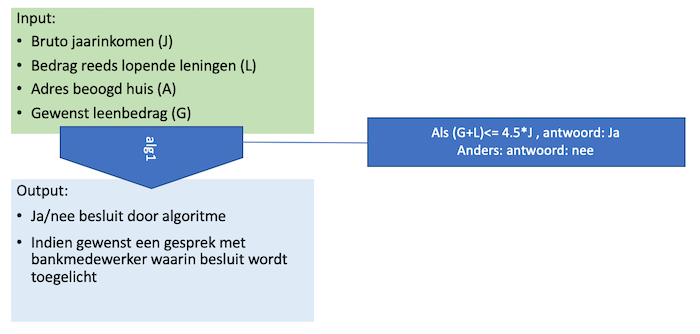
Veel problemen rond uitlegbaarheid zijn vooral praktisch van aard: deel je het besluit en de gebruikte inputs met de aanvrager? Wordt de factor 4.5 bijgesteld als de rente verandert? Wie heeft deze factor bepaald? Is er getest of dit algoritme tot goede besluiten leidt? Wat gebeurt er als iemand’s inkomen onduidelijk is? Veel van de discussie over de toepassing van AI gaat dus over praktische aspecten.
Moeilijk uitlegbare algoritmes
In de praktijk gebruiken veel bedrijven data science algoritmes en nog weinig bedrijven ‘echte AI’. Een voorbeeld van een data-science-algoritme is hieronder weergegeven. Dit algoritme is technisch goed uitlegbaar: het is een optelsom van een aantal factoren. Het aantal factoren en het aantal parameters maakt het toepassen van dit model echter al moeilijker.
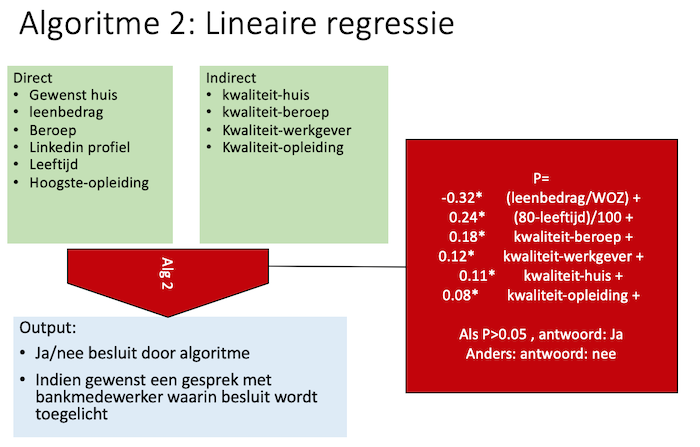
In dit model worden er kwaliteits-scores opgevraagd op basis van input van de gebruiker, waardoor het voor de betrokkene niet duidelijk is wat welke gegevens worden gebruikt. Ook is niet helemaal duidelijk hoe de kwaliteits-score bepaald worden. Hier kan men verschillend over denken. Tot slot bevat de formule zeven parameters, die gevarieerd kunnen worden. Deze variabelen worden vaak zelf weer met algoritmes berekend uit trainings-data. Om te bepalen of het algoritme goed werkt en eerlijk is, zou een toezichthouder ook naar deze trainingsdata moeten kijken.
Model-updates
Voor de praktijk van toezicht op algoritmes is het belangrijk om te weten dat parameters vaak herberekend worden omdat er nieuwe data beschikbaar is. Dit is een zogenaamde model-update. Hieronder is een typisch voorbeeld te zien.

In dit voorbeeld zijn vier parameters veranderd op basis van nieuwe data. De volgende vragen zijn interessant om te bespreken:
- Moet elke update opnieuw getest en beoordeeld worden? Moet de FG hierbij betrokken zijn? Hoe uitgebreid moeten de testen zijn?
- Als iemand’s aanvraag afgekeurd is onder het oude model, maar goedgekeurd zou worden in het nieuwe model, moet je de persoon dan informeren en opnieuw laten inzenden?
- Moet je updates publiceren? Mogen mensen hun scores en de parameters weten?
De conclusie van dit voorbeeld is dat toezicht op algoritmes ook deels een praktisch probleem is. Algoritmes worden wekelijks of dagelijks opnieuw getraind en moeten dan ook opnieuw gecontroleerd worden. Er moet sprake zijn van goed versiebeheer en ook logging van besluiten. Bovendien is het geven van inzage lastig, omdat je vaak veel data moet delen, ook over het model zelf. Er zijn zelfs vragen over eigenaarschap van data: mag elke nieuwe aanvraag toegevoegd worden aan de trainingsdata, of is hier apart toestemming voor nodig? Veel AI-bedrijven bewaren alle data die zij ontvangen.
Onderzoek naar uitlegbaarheid
Het vorige algoritme roept al veel vragen op, maar is in feite nog een technisch eenvoudig algoritme. De nieuwste AI-algoritmes zijn nog complexer. Een voorbeeld van een echt AI-algoritme, gebaseerd op een neuraal netwerk, is hieronder weergegeven. Dit algoritme heeft 1800 inputs, gebaseerd op iemands volledige betaalgeschiedenis.
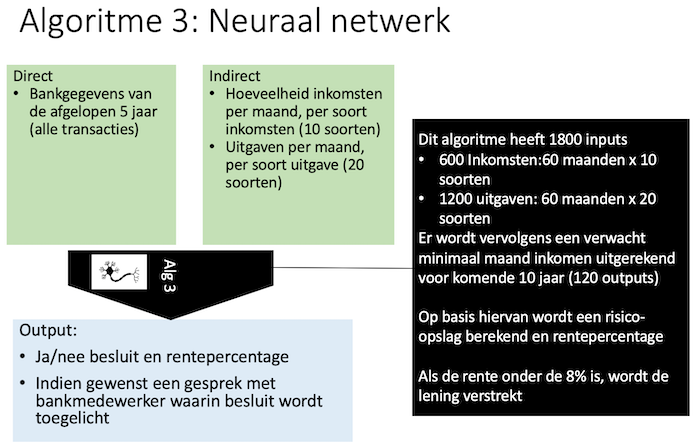
Bij dit algoritme is er een technisch uitlegbaarheidsprobleem: Het is voor de ontwikkelaars al niet duidelijk wat het algoritme doet, laat staan voor de bankmedewerkers. Het is goed mogelijk dat het algoritme moeilijk te begrijpen besluiten neemt, bijvoorbeeld mensen die veel geld in april uitgeven maar niet in november vaker afkeuren. Het is ook mogelijk dat het algoritme op basis van het uitgavenpatroon kan herkennen of iemand man of vrouw is, en dus onbewust discrimineert. Men spreekt wel van een black-box-algoritme: we kunnen de inputs en uitkomsten zien, maar de werking van het algoritme zelf niet.
Onderzoekers doen veel onderzoek naar algoritmes die uitleg kunnen genereren. de bekendste algoritmes zijn LIME en SHAP. Met deze technieken kan men grafieken maken die aangeven wat de invloed van elke input is. Deze algoritmes kunnen vervolgens gebruikt worden samen met AI-gebruiks-tools, inclusief die van het Nederlandse Deeploy. Met dit soort tools houden bedrijven controle over hun modellen, data, besluiten en gegeven uitleg. Voor gebruikers blijft het echter lastig om echt te begrijpen waarom zij afgewezen worden, ondanks de mooie grafieken. En voor toezichthouders betekent het dat zij zich moeten verdiepen in datasets, grafieken, versiebeheer en het testproces. Niet onmogelijk maar wel een nieuwe opgave.
Meer informatie
De volledige presentatie van deze website kan men hier downloaden: 20230601 DagvdFG Otterloo AI. Meer informatie over uitlegbare AI is te vinden bij de Hogeschool Utrecht. Wie zelf aan de slag wil met machine learning kan gebruik maken van de Utrecht Housing Dataset. Het onderwerp AI wordt ook regelmatig besproken bij de beroepsvereniging NVBI.
Dr. Sieuwert van Otterloo is IT-deskundige met kennis van ISO 27001, NEN 7510, software-kwaliteit, projectmanagement, privacy, en verantwoord gebruik van AI. Hij is ISO 27001 en NEN 7510 auditor, doet onderzoek bij VU en HU en geeft advies bij organisaties door heel Nederland. Hij oprichter en directeur van ICT Institute.